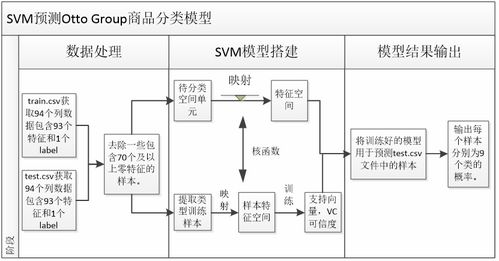
在零售和电商领域,商品识别是优化用户体验、提升推荐系统准确性的核心技术之一。Otto Group作为全球领先的电商企业,其公开的商品识别数据集为研究和实践提供了宝贵资源。本文旨在详细阐述如何利用Python对Otto Group商品数据进行系统化的数据处理,为后续的识别模型构建奠定坚实基础。
一、数据理解与加载
Otto Group商品识别数据集通常包含大量商品条目,每条记录由商品ID、多个特征属性(如商品类别、品牌、颜色、材质等)以及目标分类标签组成。数据格式常为CSV或JSON。我们首先使用Pandas库进行加载与初步探索。
`python
import pandas as pd
import numpy as np
加载数据集
data = pd.readcsv('ottoproduct_data.csv')
print(f"数据形状: {data.shape}")
print(data.head())
print(data.info())`
通过describe()和value_counts()方法,我们可以快速了解数值特征的分布与类别特征的取值情况,识别潜在的缺失值与异常值。
二、数据清洗
高质量的数据是模型成功的基石。清洗步骤主要包括:
- 处理缺失值:对于少量缺失,可采用众数、中位数或基于其他特征的预测进行填充;若缺失严重,则考虑删除该特征或样本。
- 处理异常值:通过箱线图或标准差方法检测并处理异常数值,避免其对模型产生干扰。
- 格式统一:确保文本类特征(如品牌名)的大小写、空格一致,避免因格式问题导致识别错误。
`python
# 示例:填充缺失值
data['color'].fillna(data['color'].mode()[0], inplace=True)
示例:处理异常值(假设'price'为数值特征)
Q1 = data['price'].quantile(0.25)
Q3 = data['price'].quantile(0.75)
IQR = Q3 - Q1
data = data[~((data['price'] < (Q1 - 1.5 IQR)) | (data['price'] > (Q3 + 1.5 IQR)))]`
三、特征工程
特征工程是提升模型性能的关键环节,旨在从原始数据中提取更有信息量的特征。
- 特征编码:将类别特征(如商品类别、品牌)转换为数值形式。常用方法包括标签编码(Label Encoding)和独热编码(One-Hot Encoding)。对于高基数类别,可考虑目标编码(Target Encoding)或嵌入(Embedding)。
- 特征构造:基于领域知识,组合或衍生新特征。例如,从商品描述中提取关键词,或计算价格与平均价格的比值等。
- 特征缩放:对于基于距离的模型(如KNN、SVM),需对数值特征进行标准化(StandardScaler)或归一化(MinMaxScaler),使其处于相近的量纲。
`python
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, StandardScaler
标签编码示例
le = LabelEncoder()
data['categoryencoded'] = le.fittransform(data['category'])
独热编码示例(需谨慎处理高维特征)
data = pd.get_dummies(data, columns=['brand'], prefix='brand')
标准化示例
scaler = StandardScaler()
data[['price', 'weight']] = scaler.fit_transform(data[['price', 'weight']])`
四、数据分割
为避免过拟合,需将数据划分为训练集、验证集和测试集。通常按比例(如70%-15%-15%)随机分割,并确保类别分布均衡(可使用分层抽样)。
`python
from sklearn.modelselection import traintest_split
假设X为特征,y为目标标签
X = data.drop('targetclass', axis=1)
y = data['targetclass']
Xtrain, Xtemp, ytrain, ytemp = traintestsplit(X, y, testsize=0.3, stratify=y, randomstate=42)
Xval, Xtest, yval, ytest = traintestsplit(Xtemp, ytemp, testsize=0.5, stratify=ytemp, random_state=42)`
五、处理不平衡数据
商品识别数据集中,各类别商品的数量可能存在严重不平衡。为提升少数类的识别效果,可采用以下方法:
- 重采样:过采样少数类(如SMOTE算法)或欠采样多数类。
- 调整类别权重:在模型训练时,为少数类赋予更高的损失权重。
六、数据存储与管道化
处理完成的数据应妥善存储,如保存为新的CSV文件或Feather格式以供后续快速读取。可将整个预处理流程封装为Pipeline,确保训练与预测时数据处理的一致性。
`python
# 保存处理后的数据
data.tocsv('processedotto_data.csv', index=False)
使用Pipeline示例(需结合具体转换器)
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='most_frequent')),
('scaler', StandardScaler())
])`
###
通过以上系统化的数据处理流程,我们能够将原始的Otto Group商品数据转化为干净、规整、富含信息的特征集合。这为后续应用机器学习模型(如梯度提升树、神经网络)进行精准的商品识别奠定了坚实基础。数据处理并非一蹴而就,需根据模型反馈与实际业务需求不断迭代优化,方能实现最佳识别效果。









